简介
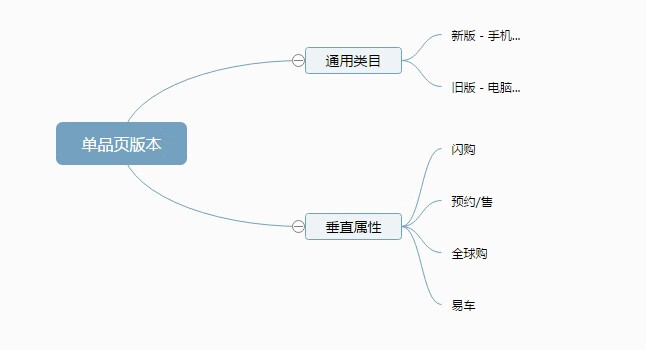
详情页也叫做单品页,域名以「item.jd.com/skuid.html」为格式的页面。是负责展示京东商品 SKU 的落地页。主要任务是展示和商品相关的信息,如:价格、促销、库存、推荐,从而引导用户进入购买流程。同时单品页有很多版本。一般分为两类。一类我们通常看到的「通用类目详情页」—— 所有类目都可以使用,一类是不经常看到的「垂直属性详情页」—— 一些有特殊属性的商品集合
首先。由于详情页大量(sku上亿)、高并发(日 pv 约 5000 万)等特性,在很长的一段时间里,单品页面都是后端程序生成静态页面使用 CDN 来解决大量、高并发的问题
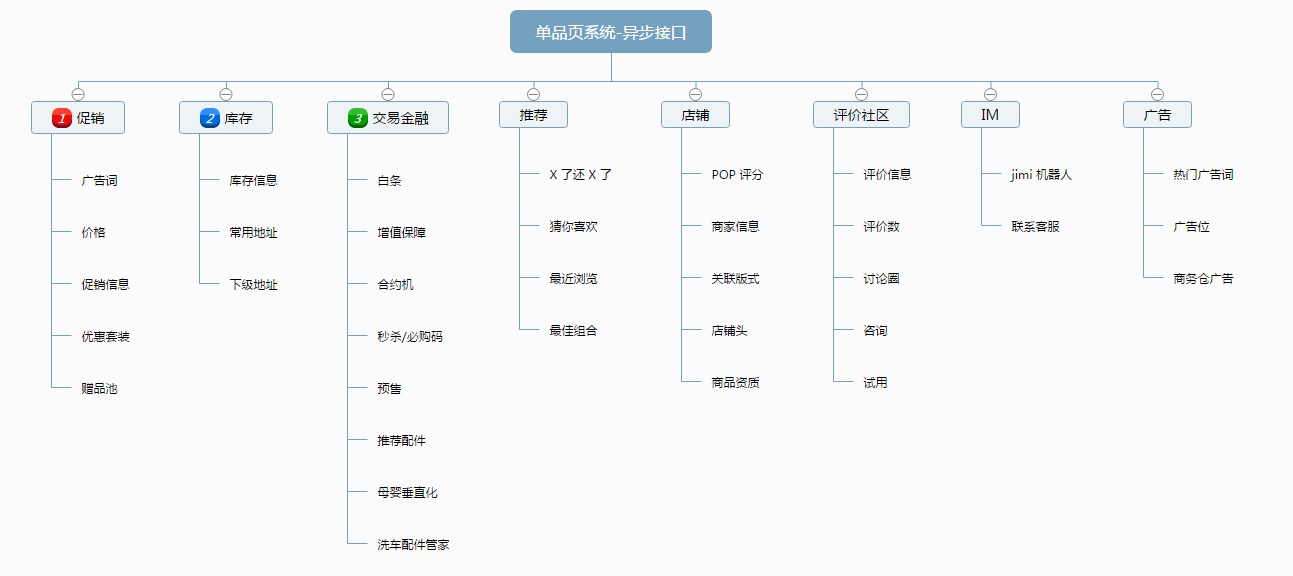
其次。单品页涉及的「三方」系统特别多,比如:促销、库存、合约、秒杀、预售、推荐、IM、店铺、评价社区。而单品页的主要任务就是展示这些系统的信息,并且适当的处理他们之间的冲突关系,而这些系统的接口一般都使用 异步 Ajax 来完成,因为 其一 CDN 无法做到页面的动态化,其二 一些系统的信息对实时性要求特别高(价格、秒杀),即使使用后端动态渲染也很难做到无缓存 0 延迟
基于上面两个原因,注定了单品页是一种重多系统业务逻辑展示型页面。重前端页面。我大概汇总了一下页面上异步接口,总共约有 30 个,页首屏的接口特别重要,接口之间几乎都有耦合关系
前端的发展历程
混沌时期
混沌时期的单品页并没有前端开发的概念。核心的功能脚本只有三个:促销价格(promotion.js)、库存地区(iplocation.js)、其它逻辑(pshow.js)。这三个脚本分别是三个不同团队的同事负责维护,当时我刚进入京东的时候在 UED 部门,负责页面脚本整体的维护工作和 pshow的开发。那时候我自己维护的 pshow.js 脚本压缩后只有 80 kb,所有的代码都是过程式的,没有任何使用模式和代码技巧,JS 最多也只被用来做个判断渲染 DOM。那时候的前端工作内容只在 UI 层面,写样式和一些交互脚本
这个阶段给我最深刻的感觉是单品页后端模板很少维护(后端架构是最老的 aspx 版本)。大多数的改动都要用 JavaScript 去动态渲染。因为后端页面是一个生成器生成的。如果页面后端模板有改动那么就需要全量的生成一次,过程可能需要几个小时
初见端倪
当我接手这个项目时刚好有一次大改版,就在这时候老大说页面上的脚本都要放在我们手里维护。然后就是一大波的重构、重写。基本上 pshow 被重写了大概 80% 其它的因为业务逻辑的问题并没有完全重写,只是做了些代码层面的优化
有一个模板引擎叫 trimPath,知道这个的估计都算老前端的了。最早的客户端 JavaScript MVC 模式代表作品,只到现在还是使用。这个阶段像评价这种完全异步加载的模块特别适合使用模板引擎来减少维护的工作量。这个时候虽然页面上的代码并不都是我们写的,但基本上前端对页面的 JavaScript 有了控制权,接下来的事情就是寻找机会逐个优化
这段时间是最痛苦的时候,维护的工作统一到前端。然后后端几乎没有变化,只是在一段时间将后台的架构从 aspx 过渡到了 java。本质上并没有什么改变。前端却做了比以前更多的事情,也是在这个时候我接手了大量的维护工作(包含全站公共库的维护)使得我意识到了一些自动化、工程化方面的重要性,后文会主要讲解,顺便说下,那时候前端自动化工具 Grunt 刚面世,但是我自己却用的是 apache ant,不过不久就切换到了 Grunt 来构建项目
拨云见日
单品页不仅重系统逻辑,也重维护
在这段时间里一方面有正常的维护类需求要做,一方面自己也不断的学习新知识为以后的改版做铺垫。不过就在这时单品页有历史意义的一次技改出现了 —— 单品页动态化技改。关于后端部分的改造细节可以去 开涛的文章 了解
总的来说这次的改版后很多数据直接从后端读取,不再从前端异步获取而且我们也做过一些异步加载的优化,多接口 combo 从统一服务吐出给前端使用。这时前端就不用再为异步接口的加载时苦脑了,只需要专注系统接口的逻辑
随着这次技改,前端的代码也迎来了模块化的时代。我们把所有的前端代码都进行了模块化然后基于 SeaJS 重写,配合 Nginx concat 功能实现了本地模块化开发,线上服务端合并
单品页前端模块的结构与划分
概览
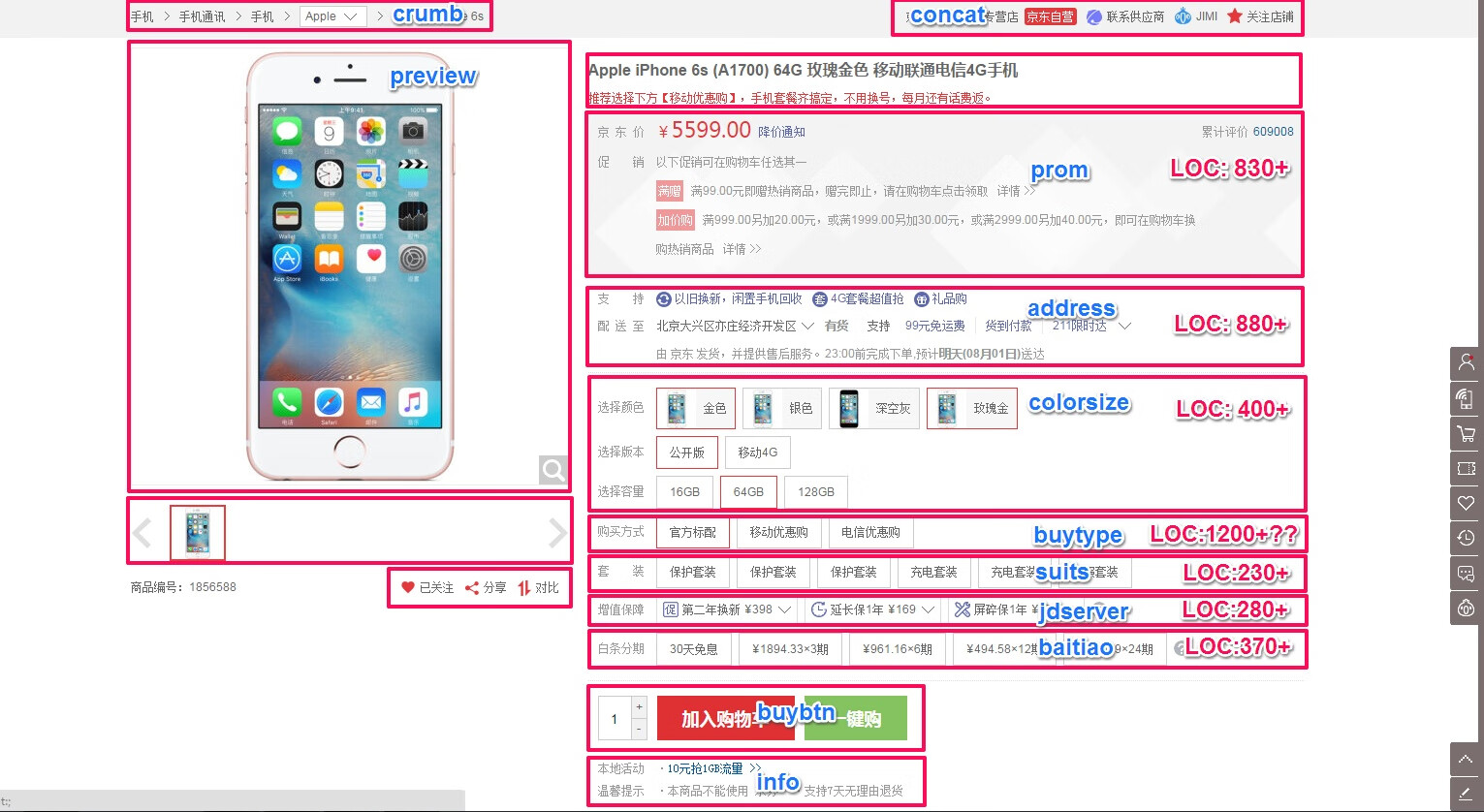
上图可以看出,基本上最核心的模块都在首屏。每个模块都有单独的一/多个脚本。代码行数(LOC)由 230+ ~ 1200+ 不等。通常来说代码行数越多代码复杂性就越高,逻辑越复杂。很难想象「购买方式」这种只有一行属性选择功能的代码行数却 高达 1200 多行。其主要原因就在于购买方式所在的系统和其它首屏核心系统(库存、促销、地址选择、白条)都有逻辑上的耦合
看着不错,然而在一个前端工程师眼里至少应该是这样的(我只取了一些典型的模块,并不是全部):
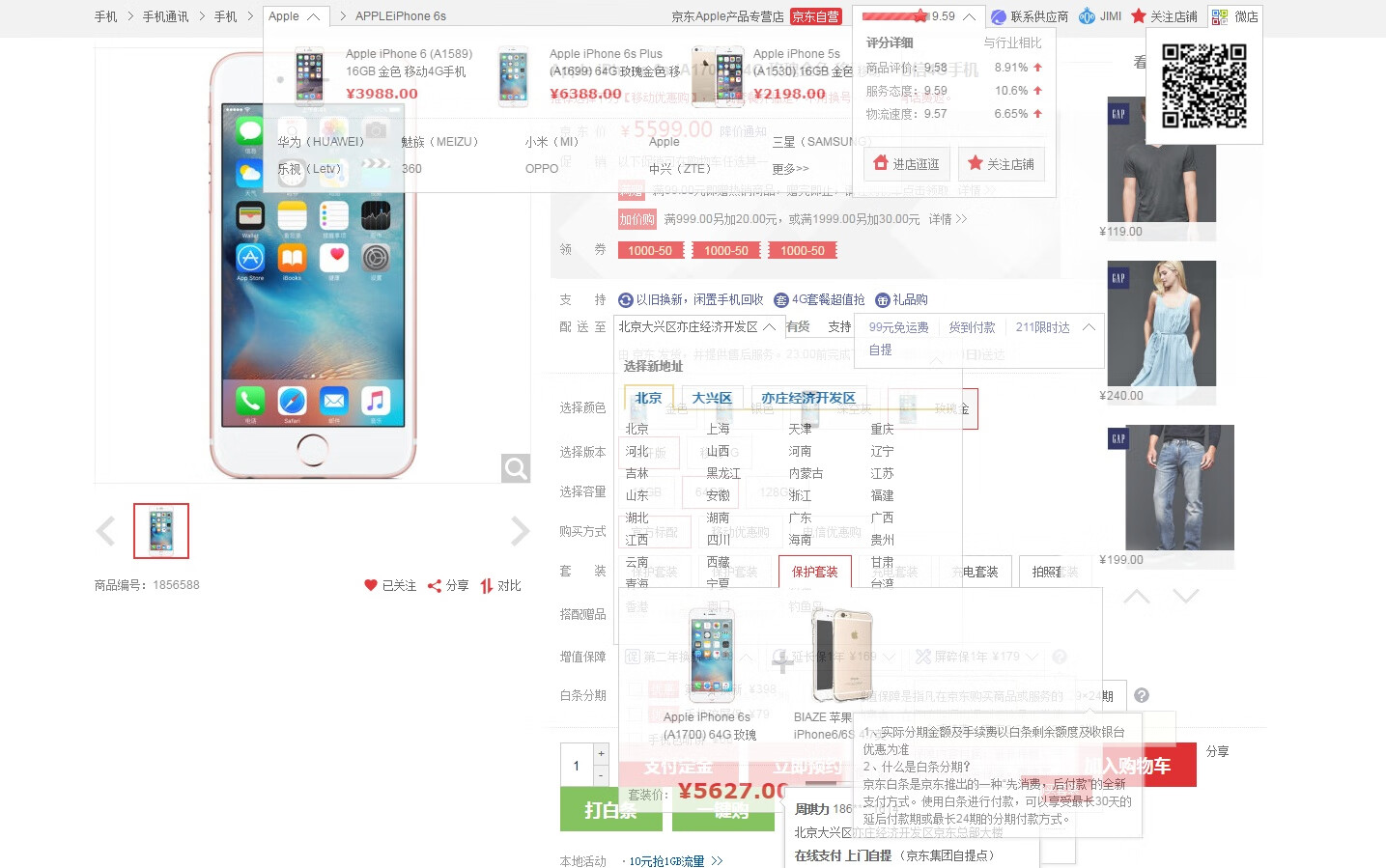
这就可以解释为什么有的时候只是加一个很小的东西我们都为考虑再三然后通过 AB 测试提取相关数据,最后后再进行决策。单品页的首屏可以说是寸土寸金
按什么维度划分模块
起初我按模块的属性划分,比如:核心、公共脚本、模块脚本。但用了一段时候以后发现这样划分在单品这种大型系统中并不科学,因为这样划分出来的代码只有划分的人知道是什么规则,其它人接手代码很难快速掌握代码架构,而且尤其在模块比较多的时候不方便维护
后来我尝试完全以功能模块在页面上出现的位置维度划分。这样以来维护起来方便多了,需要修改某个模块代码只需要对照着图里面标识的模块信息就能轻易找到代码
整体核心模块
我们按页面上的模块结构首屏划分出来这几个核心模块:
- curmb - 面包屑
- concat - 联系咨询相关店铺信息
- prom - 价格促销信息
- address - 地区库存选择,配送服务
- color - 颜色尺码
- buytype - 合约机购买方式
- suits - 套装购买
- jdservice - 增值服务
- baitiao - 白条支付
- buybtn - 购买按钮
- info - 地区提示信息
项目的整体树形结构是这样的:

模块内部结构
比如下面这个大图预览的功能,我全部放在一个文件夹里面维护,但是逻辑上的 JavaScript 模块是分离的,只是说文件夹(preview)就代表页面上的某一部分功能集合
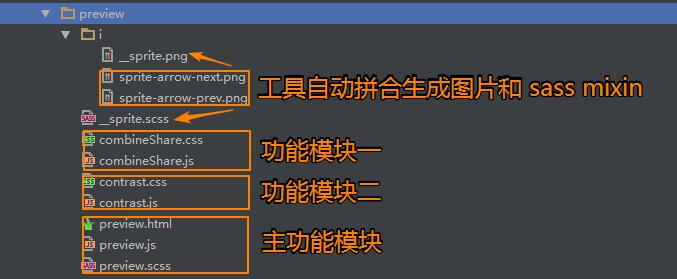
注意文件夹的命名有一定的规则:
- 模块脚本与样式名必须一样
- 需要制作 sprite 的图片统一放在 module/i 目录下面,生成的 sprite 图片也在其中
- 生成的 mixin 在模块根目录下,便于其它样式文件调用
我们再来看下自动生成生成的 __sprite.scss 是什么内容:
/* __sprite.scss 自动生成 */
@mixin sprite-arrow-next {
width: 22px;
height: 32px;
background-image: url(i/__sprite.png);
background-position: -0px -30px;
}
/* preview.scss 手动添加 */
@import "./__sprite";
.sprite-arrow-next {
@include sprite-arrow-next;
}
注意引用的 mixin 名称和我们需要手动添加的样式类名一致。当然也可以直接生成一个类名对应的样式,但是灵活性不好。比如 hover 的时候是另外一张图片就没法自动生成了
前端技能树
HTML
DOM 节点数
与重业务逻辑的页面不同,重展示的页面一般具有很高的 DOM 节点数。比如京东首页,正常情况加载完页面一共有 3500 多个 DOM 节点,基本上全部用于展示商品信息、广告图和内容布局,页面上的三方异步服务也比较少。尤其像频道页基本上没有什么业务上的逻辑,全部是静态页面。这种页面的特点是更新换代频率高,一年两三次改版很正常,CMS 做模块化后两天换个皮肤都是没问题的。但是这种思路并不适合单品页。单品页更重业务逻辑,同时展示层 UI 逻辑也有很多关系
我自己的经验是:页面上的 DOM 节点数绝对不能超过 5000 个,否则页面滚动的时候就会出现卡顿的情况,尤其是移动端
同步渲染还是异步加载
理论情况下最好做法是后端同步动态渲染页面,但是由于 Web 应用中很多功能都是用户行为驱动的。同步加载不可避免的消耗了后端服务资源。比如:非首屏模块(公共头尾、评价)、点击事件触发的 DOM 内容(异步 tab)
所以我的经验是:能放到后端做判断渲染的 DOM 就尽量放在后端(尤其是首屏)。这样做的好处有四点好处
- 后端渲染页面相对稳定,不像前端 JavaScript 动态渲染 DOM,可能因为脚本报错或者不可用造成模块都无法展示
- 可访问性、SEO 及用户体验也比较好。不会产生脚本的渲染抖动问题
- 一定程度上减少了前端渲染页面的复杂性,减少前端代码复杂度
- 逻辑统一到一个地方维护起来也方便,而且后端应该为业务逻辑负责,前端应该为展示UI 交互负责
对于异步渲染的模块来说,后端通常需要判断 「页面有什么元素」,以及元素之间的依赖对应关系;而前端需要专注于 「元素应该怎么展示」,UI 层面的交互以及模块与模块之前的逻辑关系
其实更多的时候 异步是一种没有办法的办法,也就是说异步是其它方案都解决不了的情况下才考虑的
外链静态资源
尽量使用外链 CSS 和 JavaScript 资源,一方面便于缓存,减少服务同步输出的资源浪费。IE 6 里面会有一些可怪的 bug,比如有内联样式 style 标签的页面 A 如果在另外一个页面 B 中的 link 标签中引用,那么这段 style 会在 B 页面也起作用
使用双协议的 URL
使用 // 来代替http: 和 https: 浏览器会自动适应两种协议的资源访问,兼容性较好。注意 IE 8 下使用脚本更新 src 为双协议时会出现 bug,建议使用 location.protocol 来判断然后做兼容处理
删除元素默认属性
比如 script 标签默认的 type 就是 text/javascript,如果 script 里面的内容是 JavaScript 时可以不用写 type。另外如果要在页面里面插入一段不需要浏览器解析的 HTML 片段时可以将 type 写成 text/x-template(任意不存在的 type) 用于放置模板文件,通常用来在脚本中获取其 innerHTML 而无任何负作用
给脚本控制元素加上类钩子
在脚本中取页面元素使用 J- 前缀类名,与普通样式类分离。这样做会生成很多冗余的类名,但却很好的降低了样式和脚本的耦合,并且在重构和脚本职位分开团队里会是一条最佳实践
CSS
样式分类
所有页面只共享一个 sass Mixin,里面包含了基础的 sass 语法糖、常用类(清浮动、页面整体颜色字体等)
模块级的样式分为两类:
- 与脚本无关的公共样式,单独在模块文件夹中组织。比如:按钮、标签页。全部放在 common 模块中维护
- 与脚本相关的模块级样式,与对应模块脚本放在一起,可以引用 common 中的公共样式,但不可以被其它模块引用
雪碧图
关于雪碧图 我经验是:永远不要想把所有的图标拼合在一起。按模块而不是按页面去拼 sprite 更合理,更方便维护,然后配合构建工具自动接合生成样式文件才是最好的解决方案。当然如果你的页面比较简单,那这条规则并不适用。说到这个问题我就得把珍藏多年的图片拿出来 show 一把,用事实来说明为什么把所有图片都拼在一张图上就一定是对的
早期由于年轻笃信将所有的 icon 拼在一张图上才是完美的(图 1)
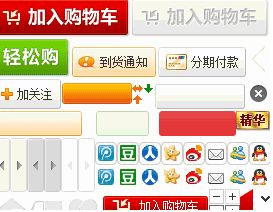
后来维护起来实在不方便,就把按钮全部单独接合起来。注意,当时的按钮都是图片,设计方面要求的很严格。加入购物车按钮做的也非常漂亮(图 2)

然后这些都不是最典型的,下面这个 promise icon 才是 (图 3)

从图里面可以看到,这个功能在第一个版本的时候只有 7 个 icon,后来不断增加,最多的时候达到 77 个。以至于当时每周都会添加两个的频率
同时这个 icon 当时接合的时候技术上也有问题:不应该把文字也切到图片里面,主要原因是早期 icon 比较少加上外边框样式对齐的问题综合选择了直接使用图片
后来我就觉得这样是不对的。然后通过和产品的沟通,说明我的考虑以及新的解决方案后得到了认同。结果就是对图片不进行拼合,后台上传经过审核的不带文字 icon,文字由接口输出,然后在产品上做了约定:icon 最多不能超过 4 个,代码里也做了相应限制。这样就能保证页面上的请求数不会太多同时方便系统维护,问题得到了解决
适当使用 DataURI
这个在一些小图片场景方面特别适合,比如 1*1 的占位图、loading 图等,不过 IE 6 并不支持这种写法,需要的时候可以加上一些兼容写法:
.ELazy-loading {
background: url(data:image/gif;base64,R0lGODlhKwAeAJEAAP///93d3Xq9VAAAACH/C05FVFNDQVBFMi4wAwEAAAAh+QQFFAAAACwDAA0AJQADAAACEpSPAhDtHxacqcr5Lm416f1hBQAh+QQJFAAAACwDAA0AJQADAAACFIyPAcLtDKKcMtn1Mt3RJpw53FYAACH5BAkUAAAALAMADQAlAAMAAAIUjI8BkL0CoxQtrYrenPjcrgDbVAAAOw==) center center no-repeat;
*background-image: url(//misc.360buyimg.com/lib/skin/e/i/loading-jd.gif);
}
关于兼容性
兼容性可以说是前端工程师在平常开发中花费很大量无意义工作的地方。关于兼容性我想说的是 如果你不愿意去说服周围的人放弃或者让他们意识到兼容性是个不可能完全解决的问题,那么你就得为那些低级浏览器给你带来的痛苦埋单
其实更好的办法是你和设计、产品沟通然后给出一种分级支持的方案。把每种浏览器定义一个级别。然后在开发功能的时候以「渐进增强」的方式。通常来讲我们的解决方案是在低级浏览器里面保证流程正常进行、模块可以使用,但忽略一些无关紧要的错位、不透明等问题,在高级浏览器里面需要对设计稿进行精确还原,适当的加上一些井上添花在细节。比如微小的动画、逻辑细节上的处理等
举个例子吧,下面这个进度条表示预约的人数,它是接口异步加载完才展示的。如果加载完就立即设置进度条宽度会显得生硬无趣,但是如果加上一点动画效果的话就好多了。然而问题又来了,如果加上动画那么逻辑上这个进度条应该是一点点的增加,对应的人数也应该是逐个增加。于是我就做了个优化,让人数在这段时间内均匀的增加。这个细节并不是很容易被人发现,但是这种设计会让用户感觉很用心而且有意思
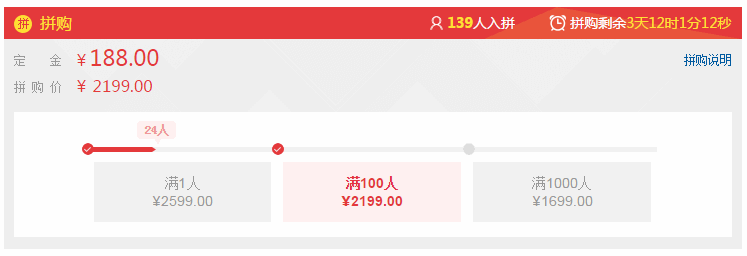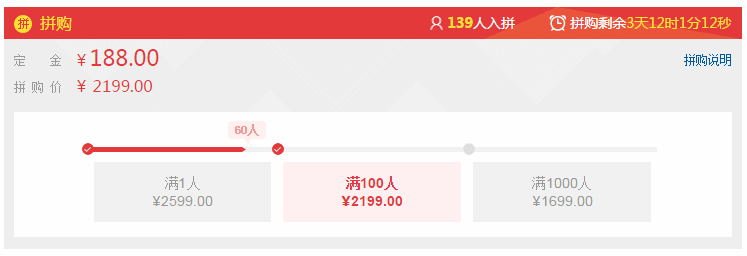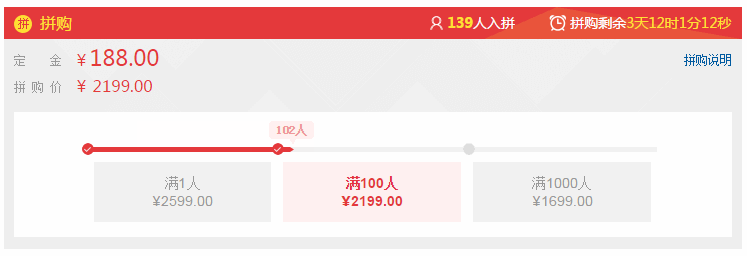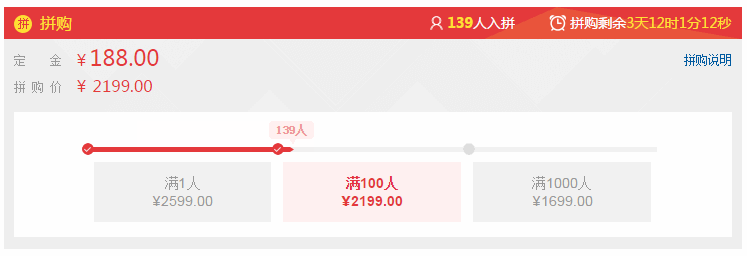
JavaScript
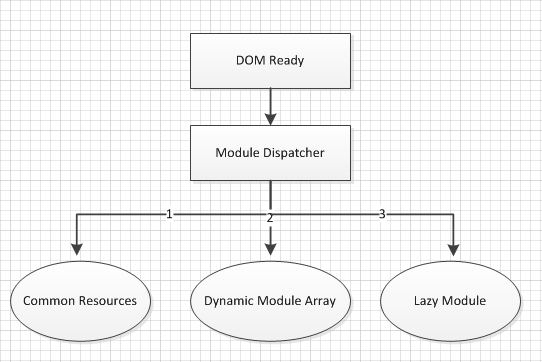
单品页的脚本加载/执行顺序:
- 等待页面准备就绪(DOM Ready)
- 准备就绪后加载入口脚本(main.js),脚本负责其它功能模块的调度,动态接合模块通过 seajs 的
require.async方法异步调用 - 公共模块(common.js)负责加初始化全局变量并挂载到 pageConfig 命名空间
- 动态模块数组,这个是后端通过程序判断处理生成的一个模块名列表。一般只包含首屏需要加载的模块
- 后加载模块(lazyinit.js)初始化,这个脚本只做一些页面滚动才加载的模块事件绑定。当模块出现在视口内再使用 require.async 异步加载模块的资源及初始化
入口脚本
大致代码如下
/**
* 模块入口(1. 公共脚本 2. 首屏模块资源 3. 非首屏「后加载模块」)
*/
var entries = [];
// 页面公共脚本样式
entries.push('common');
// 页面使用到的首屏模块(后端开发根据页面不同配置需要调用的模块)
entries = entries.concat(config.modules);
// 非首屏「后加载模块」
entries.push('lazyinit');
for (var i = 0; i < entries.length; i++) {
entries[i] = 'MOD_ROOT/' + entries[i] + '/' + entries[i];
}
if (/debug=show_modules/.test(location.href)) console.log(entries);
require.async(entries, function() {
var modules = Array.prototype.slice.call(arguments);
var len = modules.length;
for (var i = 0; i < len; i++) {
var module = modules[i];
if (module && typeof module.init === 'function') {
module.init(config);
} else {
console.warn('Module[%s] must be exports a init function.', entries[i]);
}
}
});
注意模块路径中的 MOD_ROOT 是提前在页面定义好的一个 seajs path。目的是为了把前端版本号更新的控制权释放给后端,从而解决了前后端依赖上线不同步造成的缓存延迟问题,配置脚本中只有几个定义好的路径:
seajs.config({
paths: {
'MISC' : '//misc.360buyimg.com',
'MOD_ROOT' : '//static.360buyimg.com/item/default/1.0.12/components',
'PLG_ROOT' : '//static.360buyimg.com/item/default/1.0.12/components/common/plugins',
'JDF_UI' : '//misc.360buyimg.com/jdf/1.0.0/ui',
'JDF_UNIT' : '//misc.360buyimg.com/jdf/1.0.0/unit'
}
});
还有一点,在测试环境的页面中版本号(上面代码中的 1.0.12 是一个全量的版本号)是后端从 URL 上动态读取的(使用参数访问就可以命中对应版本 item.jd.com/sku.html?version=1.0.12)。这样以来测试环境上就可以并行测试不同版本的需求,而且互不影响。当然如果不同版本的后端代码也有修改的话这样是不行的,因为后端代码也需要有个对应的版本号
不过我们已经解决了这个问题。后端会在测试环境里 动态加载后端模板 并且可以做到版本号与前端一致。这样以来配合 git 方便的分支策略就可以同时并行开发测试多个需求,不用单独配多个测试环境。什么?你还在使用 SVN!哦。那当我没说过
事件处理模型
客户端的 JavaScript 代码基本上都是事件驱动的,代码的加载解析依赖于浏览器提供的 DOM 事件。比如 onload, mouseover, scroll 等
事件驱动的的模型特别适用于异步编程,而 JavaScript 天生就是异步,所有的异步操作行为都最终会在一个回调函数(callback)中触发
比如单品页中价格接口,加载完成后需要更新 DOM 元素来展示实时价格;地区选择接口加载完成后会更新配送信息、库存/商品状态等,伪代码如下:
/* onPriceReady 和 onAreaChange 可以认为都是一个 Ajax 异步函数调用
* code 1 和 code 2 执行到的时间是不确定先后顺序的
*/
/* prom.js */
onPriceReady(function(price) {
// code 1
$('#price').html(price);
});
/* address.js */
onAreaChange(function(area) {
// code 2
$('#stock').html(area.stockInfo);
});
上面的两段代码分别在两个脚本中维护,因为他们的逻辑相对独立。早期并没有关联关系。后来需求有变,他们之间需要共享一些对方的数据(切换地区后需要重新获取价格数据并展示)。但是物理上又不能放在一起通过使用全局变量的方式共享,而且它们都是异步加载接口后才取到数据的,并不好确定谁先谁后(非要做到那就只能用全局变量双向判断)。所以这样并不能很好的解决问题,而且代码的耦合度会成倍增加
这时候我们引入了一种设计模式来解决这种问题 —— 发布者/订阅者,我们把这种模式抽象成了自定义事件代码来解决这一问题。这段代码是由 YUI 核心开发者 Nicholas C. Zakas 实现的。代码很简单,事件对象主要有两个方法 addListener(type, listener) 和 fire(event)
于是我们重构了上面的伪代码:
/* prom.js */
// 在代码中注册一个地区变化事件,获取变化后的地区 id
// 然后重新请求价格接口并展示
Event.addListener('onAreaChange', function(data) {
getAreaPrice(data.areaIds)
});
onPriceReady(function(price) {
$('#price').html(price);
Event.fire({
type: 'onPriceReady',
data: 'Any data you want'
})
});
/* address.js */
onAreaChange(function(area) {
$('#stock').html(area.stockInfo);
// 在地区变化后除了做自己该做的事情以外
// 触发一个名为 onAreaChange 的事件,用来
// 通知其它订阅者事件完成,并传递地区相关参数
// 这个时候在 onAreaChange Ajax 回调函数
// 中就只需要关心自己的逻辑,其它模块的耦合关系
// 交给它们自己通过订阅事件来处理
Event.fire({
type: 'onAreaChange',
data: area.ids
})
});
需要注意的一点是,必须确保事件先注册后触发执行,也就是说先 addListener, 再 fire
一些典型的性能优化点
基本上客户端的 JavaScript 性能问题都来自于 DOM 查找和遍历,在用于的时候一定要小心,可能不经意的一个操作就会损失很多性能,尤其在低端浏览器中。顺便多说一点,现代的 JavaScript 解释器本身是很快的,语言层面的性能问题很少遇到。DOM 查找慢是因为 浏览器给 JavaScript 访问页面提供的一套 DOM API 本身慢
- 缓存 DOM 查找,同时 DOM 查找不要超过 2000 个,低级浏览器会卡顿
- 不要使用链式调用 find,如:
find('li').find('a')而是find('li a') - 在切换元素显示状态的时候,如果元素很多。优先使用
show()/hide()方法,而不是css('display', 'block/none')前者有缓存,后者会强制触发 reflow - 给节点添加
data-xx属性在存放一些数据,通过使用 jQuery 的data('xx')方法取更高效,减少 DOM 属性访问 - 高密度事件(scroll, mousemove)触发场景请使用节流方法
- 使用事件代理,而不是直接绑定。如果不确定代码被调用次数,可以先解除绑定再绑定具有命名空间的事件处理函数
- 尽量少用 DOM 动画,使用 CSS 3 动画代替
前端工程化
原由
前端工程化其实并不是最近两年才有的概念。大约在 2013 年的时候 Grunt 问世的时候就已经有所涉及。这类打包工具主要的目的是自动化一些开发流程,我最早使用 Grunt 来构建代码的时候只解决了三个问题:
- 合并压缩优化样式脚本
- 上线完自动备份
- 单个文件打包到多目录(历史原因一个文件线上的路径有两种,需要传两个目录)
当时我还在组内做过一个分享,有兴趣的可以去围观一下 Best Workflow With Grunt
其实这些工具出现的原因是:当时前端领域的各种基础设施很缺乏,而前端的工作内容又相对零散。工作时需要开很多的软件。再加上 JavaScript 语言本身也很弱,就连包管理这种基础的东西也没有内置,以至于模块化要通过一些第三方类库来实现,比如:RequireJS, SeaJS
工具的重要性可以在我之前的一个分享中找到 前端开发工具系列
现状
如今前端工程的生态环境由于 NodeJS 的出现已经变得很好了。你可以根据自己的需求选一个合适的直接用到项目里面。像 Grunt, Gulp, browserify, webpack 等。不过要明白这些工具的出现从另一方面证明了前端开发天生存在很多的问题:
- HTML 从诞生到 HTML 5 之前几乎没有任何变化,DOM 性能天生缺失。所以才有了 Virtual DOM 这种东西
- CSS 只是一门描述型的语言,没有变量、逻辑控制、语句。所以才出现了 Sass, Less 这种预编译工具
- JavaScript 号称「高阶的(high-level)、动态的(dynamic)、弱类型的(untyped)解释型(interpreted)编程语言,适合面向对象(oop)和函数式的(functional)编程风格」的编程语言,但是语言本身有很多问题(ES 6 之前)。不适合大型项目的开发、没有一些高级特性的支持、同时被其它语言诟病的 callback 风格、单线程执行等。所以才出现了像 TypeScript, Babel 这种编译成 JavaScript 代码的语言
这些问题几乎都是历史性的原因和兼容性因素造成的。作为一名好的前端工程师要看清楚现状,然后按自己项目的需求去定制一些前端工程化的方案,而不是随波逐流。
选择
其实现在自己开发一套前端工程化/自动化流程的成本已经很低了,你只需要学习一些 NodeJS 的知识,配合 NPM 包管理机制,随手就搞出一个构建工具出来。因为并不需要你去实现什么东西,所有的东西都有现成的包。脚本压缩有 UglifyJS,CSS 优化有 CSS-min,图片压缩优化有 PNG-quant 等等。你只需要想清楚自己要达到什么目的,解决什么问题就可以抄家伙自己写一套工作流出来
我自己的经历也从 Grunt, GulpJS 到现在自造轮子。自己根据需求开发出来一套集成的打包工具,有兴趣的可以去围观一下 Wooo
当然你也可以不用任何打包工具,自己写一些 NPM Script 来完全定制化项目开发/测试/打包流程。我猜这也是为什么现在类似 Grunt 不再那么火,Gulp 迟迟没有发布 4.0 版本的原因。写一个构建工具的成本太低了,而且这种集成的工具很难满足差异的开发需求。君不知已有人意识到了这一点么why-i-left-gulp-and-grunt-for-npm-scripts
程序、设计、产品
我始终认为程序、设计是为了产品服务的。好的产品是要重视设计的,好的(前端)工程师是要有一些审美素养
其实很多时候技术解决方案都是要根据产品的定位来设计的,了解产品需求以后才能定制出真正合适的高效的解决方案。好比前面讲到的那个 sprite 案例,如果一开始就和产品讨论好方案后来也不可能有那种失控的情况发生。在产品形成/上线前期能发现问题比上线后发现问题更容易解决
这部分内容和代码无关,就不多说了。然而早年我还有一次分享关于前端、改变
总结
关于单品页的前端开发本篇文章只是冰山一角,还有很多没有提及,每个小东西都可以单独写一篇文章来分享。随后希望可以有更多的总结和分享